5.1. Global Memory Access#
A DSP kernel implemented in the PL exchanges data with the PS host via global memory (DDR4 on the RFSoC 4x2 board, see Section 1.1) that is outside of the RFSoC device. For Vitis HLS as discussed before, access to the global memory is through array (and/or pointer-to-array) arguments of the top-level function of the DSP kernel. By default, Vitis HLS creates a single AXI4 memory mapped (
m_axi) interface,m_axi_gmem, through which access to all the array arguments of the top-level function is bundled.Under the
m_axiprotocol:Reading from the global memory must be preceded by a read request.
Writing to the global memory must be preceded by a write request and followed by a write acknowledgement (response).
The read latency of the global memory is defined as the time taken from when the kernel sends out a read request to when the data requested is received by the kernel. Similarly, the write latency is defined as the time taken from when the data is written by the kernel to when the write acknowledgement is received by the kernel.
As the global memory is not on-chip, accessing it incurs much more significant time overheads than accessing local memory on-chip. Both the read latency and write latency of the global memory are typically in excess of tens of clock cycles. Thus, if global memory access is not carefully optimized in the design of a DSP kernel, it can easily become the performance bottleneck.
There are three main optimizations that can be performed to increase the global memory access throughput under the
m_axiprotocol:port widening
burst access
caching
Vitis HLS automatically performs the optimization of burst access and port widening based on its inferencing of the kernel code. If Vitis HLS fails to infer the possibility of burst access, we may re-factor the kernel code to perform manual burst access. If manual burst access does not improve the global memory access throughput, we may then try caching.
5.1.1. Port Widening#
The maximum bit-width of an AXI4 port is 1024. Vitis HLS allows the
m_axiinterface of a kernel to have a bit-width up to 512. This maximum setting allows us to read/write 64 bytes per access to the global memory. For example, consider the following simple top-level function:#define N 8000 void top(int in[N], int out[N], int incr) { RW_Loop: for (int n=0; n<N; n++) { out[n] = in[n] + incr; } }
The arrays
in[N]andout[N]are both mapped to global memory via the defaultm_axi_gmemport. If the bit-width ofm_axi_gmemis set to that ofint(32), we may only read (write) a single element ofin(out) per access. However, if the bit-width ofm_axi_gmemis widen to 512, we can read (write) 16 elements ofin(out) per access.Vitis HLS automatically infers the opportunity to widen the bit-width of the
m_axiport. In the example above, Vitis HLS will widen the bit-width of them_axiport to the maximum value of 512 and hence only 500 accesses to the global memory are needed to read (write) the entire arrayin(out). We may use themax_widen_bitwidth=option of the interface pragma to set the maximum bit-width to which Vitis HLS may automatically widen them_axiport.If Vitis HLS fails to automatically widen the bit-width of the
m_axiport, we may manually do so by using arrays of the AP integer, AP fixed point, orhls::vectortype discussed in Section 4.4 as arguments of the top-level function of the kernel.
5.1.2. Burst Access#
Another way to improve global memory access efficiency is to aggregate multiple accesses to the global memory into a single burst access in such a way that only a single request (response) is needed for a sequence of reads (writes) to the global memory.
In the case of burst access, the read latency is re-defined as the time taken from when the kernel sends out the read request to when the first piece of data requested is received by the kernel. The write latency is defined as the time taken from when the last piece of data is written by the kernel to when the write acknowledgement is received by the kernel.
The figure below shows how the DSP kernel’s
m_axiinterface adapter generated by Vitis HLS is connected to the global DDR memory: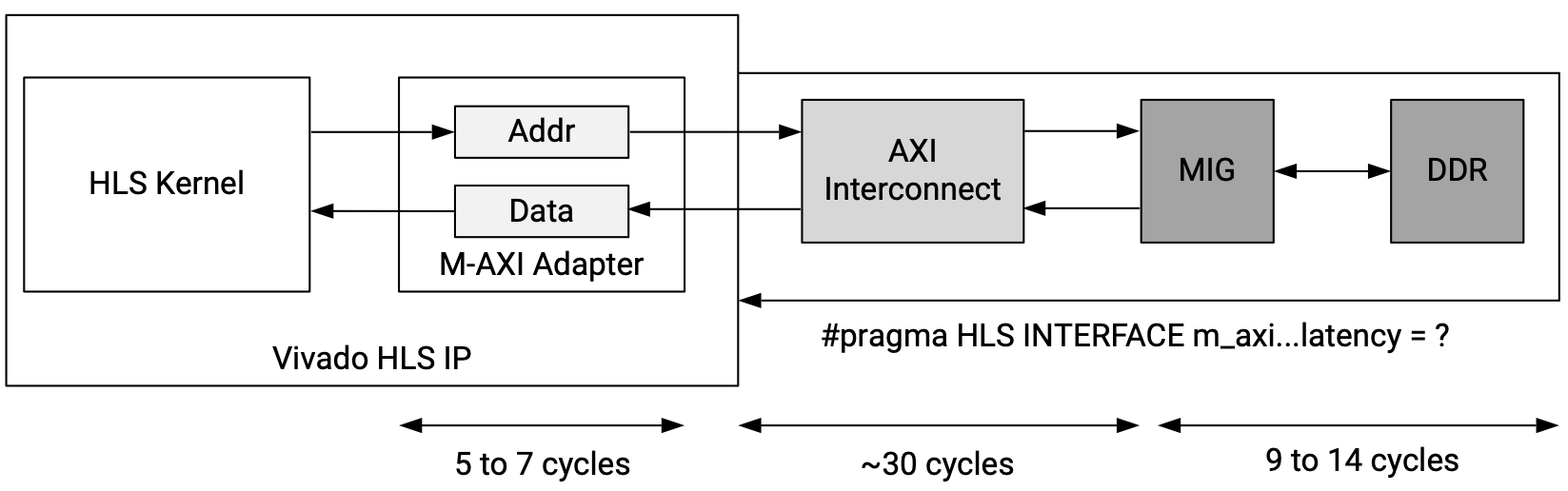
Fig. 5.1 Connection between the
m_axiinterface of a kernel and the global DDR memory (figure taken from [AMD-Xilinx24c])#During a burst access, a read request is sent to the kernel’s
m_axiinterface adapter, which serves as a buffer for all read (write) requests generated by the kernel. Them_axiadapter may cut a large access burst into smaller bursts in order to conform to the 4k-byte access limit and to avoid hogging the AXI interconnect. A request may take 5 to 7 clock cycles to go through them_axiadapter.The request is then routed through the AXI interconnect to the memory interface generator (MIG), which interfaces the off-chip DDR memory. Getting through the AXI interconnect may take about 30 clock cycles, and getting to the DDR memory and then getting the first piece of data back from the memory via the MIG may take 9 to 14 clock cycles.
The situation is similar for the write request, write data, and write response sequence. The difference is that read requests are sent by the
m_axiadapter at the first available chance but a write request will be queued until the data for all writes in the burst become available in the buffer of them_axiadapter. This conservative behavior may be changed by setting the configuration fieldsyn.interface.m_axi_conservative_modeto0(false) in the configuration file of the HLS kernel.Overall, the read (write) latency is generally non-deterministic depending on the arbitration strategy of the AXI interconnect and the memory access patterns of other hardware components. However, the value of read (write) latency is at least tens of clock cycles. Thus, burst access can significantly increase the global memory access throughput since multiple pieces of data can be contiguously read (written), needing to suffer the latency of a single read request (write response).
The interface pragma provides a number of options for us to control and fine tune the buffering and fragmentation operations for burst access in the
m_axiinterface adapter to obtain a higher global memory access throughput:latency=<value>specifies the expected read (write) latency of them_axiinterface, allowing Vitis HLS to initiate a read (write) requestvalueclock cycles before the read (write) is expected. The default setting isvalue=64. If the expected latency is set too low, the read (write) will be scheduled too soon and thus the kernel might stall waiting for the global memory. If this figure is set too high, memory access might be idle waiting on the kernel to start the read (write).max_read_burst_length=<value>specifies the maximum number of data values read during a burst access. Them_axiadapter will fragment a longer burst to short burst of this length. The default setting isvalue=16.max_write_burst_length=<value>specifies the maximum number of data values written during a burst access. Them_axiadapter will fragment a longer burst to short burst of this length. The default setting isvalue=16.num_read_outstanding=<value>specifies how many read requests can be made without a response before the AXI4 adapter stalls. This requires the adapter to have an internal read FIFO buffer of sizenum_read_outstanding*max_read_burst_length*data_word_size. The default setting isvalue=16.num_write_outstanding=<value>specifies how many write requests can be made without a response before the AXI4 adapter stalls. This requires the adapter to have an internal write FIFO buffer of sizenum_write_outstanding*max_write_burst_length*data_word_size. The default setting isvalue=16.channel=<value>specifies the channel, identified by the channel numbervalue, in them_axiadapter that an array argument of the top-level function uses.depth=<value>specifies the maximum number of data values for the simulatedm_axiadapter in the test bench to process during C/RTL co-simulation.
Unfortunately, the reports generated in the synthesis and co-simulation steps of the Vitis HLS workflow do not seem to capture the effects of setting some of these parameters when the
m_axiadapter interacts with the global memory. Hence, it may need to test these settings directly using the hardware on the RFSoC 4x2 board.
5.1.2.1. Manual Burst Access#
The
hls::burst_maxiclass provides the support for us to implement burst access to the global memory by manually controlling the burst access behavior of the kernel. There are two types of burst access, namely pipeline bursting and sequential bursting, that we may use thehls::burst_maxiclass object to implement.A pipeline burst supports the maximum number of pieces of data to be accessed with a single read request (pair of write request and write response). The “maximum number” here often refers to the tripcount of a loop. The best way to explain pipeline bursting is to consider the following example kernel code:
#include <hls_burst_maxi.h> #define MAX_N 1000 void read_task(hls::burst_maxi<int> in, int *buf, int N) { in.read_request(0, N); Read_Loop: for (int n=0; n<N; n++) { #pragma HLS loop_tripcount max=MAX_N buf[n] = in.read(); } } void write_task(int *buf, hls::burst_maxi<int> out, int N) { out.write_request(0, N); Write_Loop: for (int n=0; n<N; n++) { #pragma HLS loop_tripcount max=MAX_N out.write(buf[n]); } out.write_response(); } void top(hls::burst_maxi<int> in, hls::burst_maxi<int> out, int N) { #pragma HLS interface mode=m_axi port=in depth=MAX_N channel=0 #pragma HLS interface mode=m_axi port=out depth=MAX_N channel=1 int buffer[MAX_N]; #pragma HLS DATAFLOW read_task(in, buffer, N); write_task(buffer, out, N); }
First, we need to include the header file
<hls_burst_maxi.h>to use thehls::burst_maxi<>class template.In the top-level function
top(), we employ thehls::burst_maxi<int>-type argumentsinandoutinstead of array arguments to let Vitis HLS know that we intend to implement manual burst access.Two interface pragmas are used to set the arguments
inandoutto use channels0and1of the defaultm_axi_gmemadapter, respectively. This is a requirement by Vitis HLS that differenthls::burst_maxi<int>-type arguments must be on differentm_axiadapters or different channels if they are bundled to the samem_axiadapter. Thedepth=MAX_Noptions in the pragmas tell Vitis HLS the maximum number of pieces of data so that it can reserves enough buffering in the simulatedm_axiadapter during the C/RTL co-simulation step.In the
read_task()function, a single read request is sent to them_axiadapter to request for a burst read of all pieces of data in theRead_Loop.In the
write_task()function similarly, a single write request is sent to them_axiadapter to request for a burst write of all pieces of data in theWrite_Loop. After that, thewrite_response()method is employed to wait for a single write response returning from the global memory via them_axiadapter.Vitis HLS will not change the bit-width of a port synthesized from an
hls::burst_maxi<int>-type argument. Thus, automatic port widening will not be applied in this case.A FIFO should be configured to be the streaming buffer between the
read_task()andwrite_task()for the dataflow optimization to work efficiently. This applies to all examples below involving the dataflow optimization.
The testbench code can simply input arrays for the
hls::burst_maxi<int>-type arguments when calling the top-level function, for example as shown in the C++ code snippet below:int x[Max_N], y[Max_N]; ... top(x, y, 1000);
In a sequential burst , a smaller number of pieces of data are accessed with each single read request (pair of write request and write response). The sequence of read requests and reads (write requests, writes, and write responses) are typically all placed with a loop, as opposed to the case of a pipeline burst. Once again, the best way to explain a sequential is to consider the following example kernel code:
#define BURST_LEN 2 void read_task(hls::burst_maxi<int> in, int *buf, int N) { Read_Loop: for (int n=0; n<N/BURST_LEN; n++) { #pragma HLS loop_tripcount max=MAX_N/BURST_LEN #pragma HLS pipeline II=BURST_LEN in.read_request(n*BURST_LEN, BURST_LEN); Read_Burst_Loop: for (int k=0; k<BURST_LEN; k++) { buf[n*BURST_LEN+k] = in.read(); } } } void write_task(int *buf, hls::burst_maxi<int> out, int N) { Write_Loop: for (int n=0; n<N/BURST_LEN; n++) { #pragma HLS loop_tripcount max=MAX_N/BURST_LEN #pragma HLS pipeline II=BURST_LEN out.write_request(n*BURST_LEN, BURST_LEN); Read_Burst_Loop: for (int k=0; k<BURST_LEN; k++) { out.write(buf[n*BURST_LEN+k]); } out.write_response(); } } void top(hls::burst_maxi<int> in, hls::burst_maxi<int> out, int N) { #pragma HLS interface mode=m_axi port=in depth=MAX_N channel=0 num_read_outstanding=36 #pragma HLS interface mode=m_axi port=out depth=MAX_N channel=1 num_write_outstanding=36 int buffer[MAX_N]; #pragma HLS DATAFLOW read_task(in, buffer, N); write_task(buffer, out, N); }
With sequential bursting, there may be gaps in accessing the global memory via the AXI interconnect, and thus may not be as efficient as pipeline bursting.
Pipelining the loop helps to reduce these memory access gaps. However, pipeling the loop may push a stream of read (write) requests in a row to the
m_axiadapter. Therefore, we may need to increase the values ofnum_read_outstandingandnum_write_outstandingin order to buffer all these requests in the adapter. Otherwise, the kernel may stall when trying to push read (write) requests to them_axiadapter, creating back more memory access gaps.
Caution
The latency estimates given in the synthesis report for burst access, in particular sequential bursting, may not be accurate because only the nominal read and write latency values, but not the behaviors of the
m_axiadapter, are considered in the reporting process. More accurate latency estimates are produced in the C/RTL co-simulation, which models the behaviors of them_axiadapter.
5.1.2.2. Automatic Burst Access#
Vitis HLS performs automatic burst access optimization by inferring from the kernel code opportunities to implement pipeline and/or sequential bursting on a per function basis:
Vitis HLS first looks for sequences of statements that perform global memory access in the body of a function to implement sequential bursting across the sequences.
Vitis HLS then looks at loops to try to infer possibilities of pipeline bursting. If pipeline bursting can not be inferred for a loop, Vitis HLS will try to implement sequential bursting for the loop.
Vitis HLS will determine pipeline bursting for a loop if all the following conditions are satisfied:
The loop must contain either all reads or all writes.
The memory locations of the reads must be monotonically increasing as the loop iterates.
The reads (writes) must be consecutive in memory.
The number of reads (writes), i.e., the burst length, must be determined before the read (write) request is sent.
If more than one array is bundled to the same
m_axiinterface, bursting can be implemented only for at most one array in each direction (read or write) at any given time.If in a code region accesses of more than one array in the same channel and same bundle are in the same direction, no pipeline bursting will be implemented for any of these accesses.
There must be no dependence issues between a burst access is initiated and completed.
For example, consider the top-level function in Section 5.1.1. Since there are both reads and writes in the loop
RW_Loop, Vitis HLS will automatically implement sequential bursting with them_axiport widened to 512 bits. Note that for automatic port widening, the total number of bits in a burst must be divisible by the widened port bit-width. In the example, as \(8000*32\) is divisible by \(512\), Vitis HLS automatically widens the bit-width to 512 bits.Consider another example as shown below:
#include <assert.h> void read_task(int *in, int *buf, int N) { assert(N%8==0); Read_Loop: for (int n=0; n<N; n++) { #pragma HLS loop_tripcount max=MAX_N buf[n] = in[n]; } } void write_task(int *buf, int *out, int N) { assert(N%8==0); Write_Loop: for (int n=0; n<N; n++) { #pragma HLS loop_tripcount max=MAX_N out[n] = buf[n]; } } void top(int *in, int *out, int N) { #pragma HLS interface mode=m_axi port=in depth=MAX_N #pragma HLS interface mode=m_axi port=out depth=MAX_N int buffer[MAX_N]; #pragma HLS DATAFLOW read_task(in, buffer, N); write_task(buffer, out, N); }
Vitis HLS in this case infers and implements pipeline bursting because all the conditions for pipeline bursting are satisfied in this example.
In this example, the loop bounds of
Read_LoopandWrite_Loopare variables. Since Vitis HLS can not infer the burst length during synthesis, it will not perform automatic port widening. To help Vitis HLS infer the best possible widened port bit-width, we may add anassertstatement just right before each loop that accesses the global memory as shown in the example above. Theassertstatements beforeRead_LoopandWrite_Loopbasically inform Vitis HLS that the burst length is divisible by 8, and hence the port bit-width can be widened to 256 bits.
5.1.3. Caching#
Caching creates a buffer in the
m_axiadapter to store a contiguous block of data that is pre-read from the global memory. The idea of caching is based on the usual programming scenarios that the same block of memory locations are read repetitively over a short period of time. Thus, pre-reading the block of data from the global memory (by bursting) and storing the data temporarily in the caching buffer in the adapter may statistically reduce the read latency.Caching can be invoked in Vitis HLS by using
#pragma HLS cache. For example, consider the following piece of kernel code:#define N 1000 void top(int in[N], int out[N]) { #pragma HLS interface mode=m_axi port=in bundle=gm0 num_read_outstanding=36 #pragma HLS interface mode=m_axi port=out bundle=gm1 num_write_outstanding=36 #pragma HLS cache port=in lines=1 depth=512 out[0] = in[0]; RW_Loop: for (int n=1; n<N; n++) { out[n] = in[n-1] + in[n]; } }
The memory location overlap and dependence in the reading process of
in[n-1] + in[n]from one iteration to the next inRW_Loopcause Vitis HLS to infer neither pipeline nor sequential bursting for the reads from the global memory. The port bit-width is also not widened as a result.Separating
in[N]andout[N]into two differentm_axiinterfaces allows Vitis HLS to infer sequential bursting for the writes.Using the cache pragma as shown reduces the latency of the loop by about 10% in this case.
The bottleneck in reducing the latency is the fact that the memory dependence in the two reads inside the body of the loop forces II=2 when pipelining the loop. One may re-factor the code in
RW_Loopto do a single read frominand a single write tooutin each iteration to reduce the II to 1 clock cycle (see Section 5.2).