3.4. Data Flow Graph Execution#
As discussed in Section 3.2, it is preferable to follow the producer-consumer model in the HLS development of a DSP kernel by decomposing the kernel into a network of tasks connected together by streaming buffers to form a data flow graph. Communications and synchronization between the tasks are through the streaming buffers, which are also often referred to as channels.
3.4.1. Task Model#
To support this data flow graph architecture, each task should be constructed in accordance to the model depicted in the figure below:
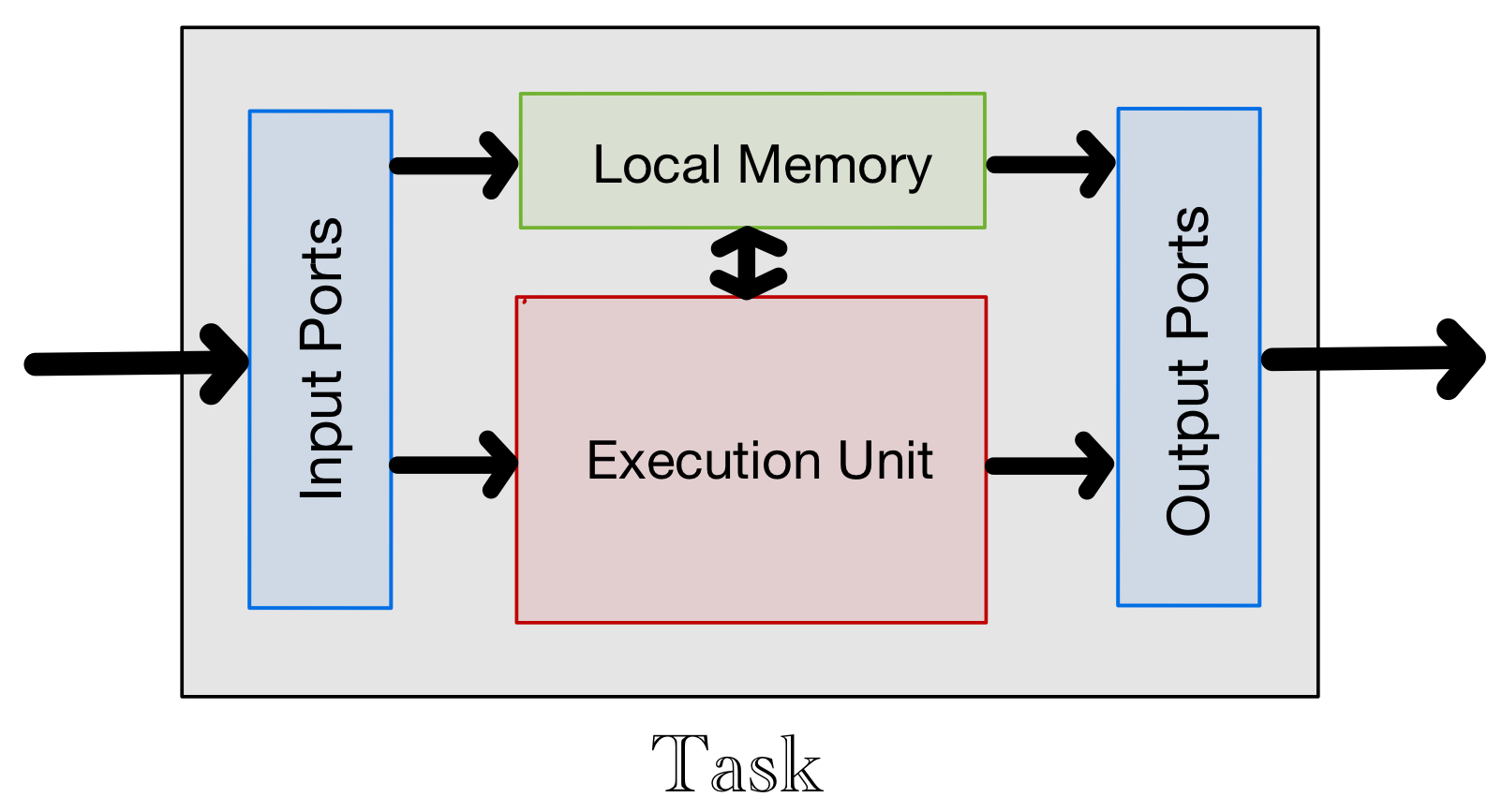
Fig. 3.2 Task Model.#
Based on this model, a task consists of:
an execution unit which performs the DSP function of the task,
some local memory (BRAM, URAM, and/or registers) that stores data accessible only within the task, and
a collection of input and output ports that respectively connect to streaming buffers (channels) and other connections input to and output from the task.
To conform to the task model in Fig. 3.2, a task can be specified by a C/C++ function. Vitis HLS infers the various components of a task function in the following way:
The execution unit is specified by the operations defined in the body of the function.
The variables in the body of the function are mapped to local memory. Vitis determines the types of PL resources to be used for different types of variables. Registers and RAM are typically used to implement scalar variables and arrays, respectively.
The arguments of the task function are mapped to I/O ports. Input ports for scalar arguments are connected to registers and ports for arrays and streams are connected to streaming buffers. The directions of the ports are inferred from the read/write operations on the streaming buffers defined in the body of the function.
Vitis HLS supports both blocking and non-blocking read and write semantics for accessing the connected streaming buffers in a task. A blocking read from an empty buffer holds the reading process until the buffer becomes non-empty. A non-blocking read from an empty buffer returns uninitialized or the last read data. Similarly, a blocking write to a full buffer holds the writing process until the buffer becomes not full. A non-blocking write to a full buffer results in the data being dropped.
Vitis HLS supports a data-driven model and a control-driven model to structure the execution of tasks in a data flow graph [AMD-Xilinx24c]. Details of these models will be discussed below. The use of the two models can also be mixed in a data flow graph.
3.4.2. Data-driven Execution Model#
Under the data-driven model, each task waits for and then executes when there is input data for it to process. The tasks in the data flow graph do not need to be controlled by any actions, such as function calls and data transfer, by the PS host.
We need to instantiate data-driven tasks as
hls::taskclass objects and connect them using streaming buffers to specify the data flow graph explicitly in the C++ specification of the DSP kernel. Only FIFOs, declared using the templatized C++ classeshls::stream<type, depth>andhls::stream_of_blocks<block_type, depth>, may be used as streaming buffers for data-driven tasks.The use of FIFOs and explicit connections of the data flow graph in the data-driven model allows Vitis HLS to infer opportunities for pipelining and parallelization when converting the C++ specification to RTL.
For an illustrative example of how to construct a data flow graph operating under the data-driven model, consider the C++ code snippet (taken from this example) below
void splitter(hls::stream<int>& in, hls::stream<int>& odds_buf, hls::stream<int>& evens_buf) { int data = in.read(); if (data % 2 == 0)) evens_buf.write(data); else odds_buf.write(data); } void odds(hls::stream<int>& in, hls::stream<int>& out) { out.write(in.read() + 1); } void evens(hls::stream<int>& in, hls::stream<int>& out) { out.write(in.read() + 2); } void odds_and_evens(hls::stream<int>& in, hls::stream<int>& out1, hls::stream<int>& out2) { hls_thread_local hls::stream<int, N / 2> s1; // channel connecting t1 and t2 hls_thread_local hls::stream<int, N / 2> s2; // channel connecting t1 and t3 // t1 infinitely runs func1, with input in and outputs s1 and s2 hls_thread_local hls::task t1(splitter, in, s1, s2); // t2 infinitely runs func2, with input s1 and output out1 hls_thread_local hls::task t2(odds, s1, out1); // t3 infinitely runs func3, with input s2 and output out2 hls_thread_local hls::task t3(evens, s2, out2); }
that specifies the following data-driven data flow graph:
(3.4)#\[\begin{split}\begin{equation} \boxed{\text{in}} \rightarrow t_1 \ \begin{array}{c} \stackrel{s_1}{\nearrow} {}^{\displaystyle t_2 \rightarrow \boxed{\text{out}_1}} \\ \stackrel{s_2}{\searrow} {}_{\displaystyle t_3 \rightarrow \boxed{\text{out}_2}} \end{array} \end{equation}\end{split}\]The function
odds_and_evens()is the top-level function of the DSP kernel. It has an input FIFOinand two output FIFOsout1andout2. Connections of these I/O FIFOs to outside hardware components are specified using the Vitis tool. For example, we may connect the input FIFOinto the ADC activated in the class Vitis platform described in Section 1.3.3.The data-driven tasks
t1,t2, andt3are instantiated ashls::taskclass objects as discussed above. The three tasks are specified by the functionssplitter(),odd(), andeven(), respectively. The instantiation of the data-driven tasks is similar to instantiating threads in standard C++. Indeed, the qualifierhls_thread_localbefore each instantiation of anhls::taskobject is used to ensure the thread that emulates that data-driven task starts only once and keeps the same state when called multiple times in the C simulation of the HLS code above.The data flow graph in (3.4) is explicitly connected by setting the
hls::stream<int>objectss1ands2as output FIFOs for taskt1and input FIFOs for taskst2andt3. Note that the qualifierhls_thread_localalso needs to be used for each instantiation of the local (to the DSP kernel)hls::stream<int>objects.
3.4.3. Control-driven Execution Model#
Under the control-driven model, execution of tasks in a DSP kernel is controlled by the PS host through its interactions with the kernel, such function call and parameter passing. Tasks may also access global memory in this model.
Unlike in the data-driven case, we do not need to explicitly instantiate the tasks and connect them to form the data flow graph. Instead, we may use regular sequential C++ semantics to specify the DSP kernel and indicate using
#pragma HLS dataflowthe code region for which we want Vitis HLS to infer and construct an efficient (acyclic) data flow graph with pipelining. Vitis HLS also automatically applies task-level parallelization to fully independent tasks that it detects.Decomposing the C++ specification of the dataflow region into a sequence of task functions conforming to the task model in Section 3.4.1 can help Vitis HLS to infer a more optimized data flow graph. In particular, it is recommended that the dataflow region should be written in the canonical form [AMD-Xilinx24c] for more predictable inferencing by Vitis HLS.
A dataflow region is in the canonical form if:
The task functions are not inlined.
Each task function’s return type is
void.Each task function uses only local and non-static variables.
The sequence of task functions pass data forward such that an acyclic data flow graph can be inferred from the sequence. Standard C++ scalar and array arguments can be employed to pass data from one task function to the next in the sequence. The array arguments will be mapped to streaming buffers (FIFOs or PIPOs). If a cyclic data flow graph is required, the feedback connections must use
hls::streamorhls::stream_of_blocksarguments.Array argument variables linking a producer task to a consumer task are written before read.
No conditional, loop, return, goto, exception are used to control the data flow in the sequence of task functions.
Again, it is more illustrative to consider the following piece of C++ code snippet (taken from this example) showing how to specify a control-driven data flow graph using the dataflow pragma:
typedef unsigned char data_t; void diamond(data_t I[N], data_t O[N]) { data_t c1[N], c2[N], c3[N], c4[N]; #pragma HLS dataflow A(I, c1, c2); B(c1, c3); C(c2, c4); D(c3, c4, O); } void A(data_t* in, data_t* out1, data_t* out2) { #pragma HLS inline off Loop0: for (int i = 0; i < N; i++) { #pragma HLS pipeline data_t t = in[i] * 3; out1[i] = t; out2[i] = t; } } void B(data_t* in, data_t* out) { #pragma HLS inline off Loop0: for (int i = 0; i < N; i++) { #pragma HLS pipeline out[i] = in[i] + 25; } } void C(data_t* in, data_t* out) { #pragma HLS inline off Loop0: for (data_t i = 0; i < N; i++) { #pragma HLS pipeline out[i] = in[i] * 2; } } void D(data_t* in1, data_t* in2, data_t* out) { #pragma HLS inline off Loop0: for (int i = 0; i < N; i++) { #pragma HLS pipeline out[i] = in1[i] + in2[i] * 2; } }
The top-level function of the DSP kernel is
diamond(). The dataflow region is specified as the scope of the function by the dataflow pragma inside the function. The arraysIandOin the function arguments are mapped to global memory. The PS host calls this top-level function to start the DSP kernel, and transfers data in and out of the kernel by accessing the global memory.The functions
A,B,C, andDdefine four tasks. The way that the arraysc1,c2,c3, andc4enter as the arguments of the task functions lets Vitis HLS infer the diamond-shape data flow graph in (3.2) with task-level pipelining and the independency between tasks \(B\) and \(C\) for parallelization.By default, the arrays
c1,c2,c3, andc4are mapped to PIPOs. In this example, users can also choose to map the arrays to FIFOs as they are accessed sequentially as shown in the bodies of the task functions. The choice of streaming buffer type can be specified in the configuration file in Vitis HLS (see Lab 2) or by using#pragma HLS stream.It can be easily check that the dataflow region is specified in the canonical form in this example. Instruction-level pipelining is also requested by the pipeline pragma in the loop in each task function (see Section 4.2 for more discussion).
3.4.4. Mixed Data- and Control-driven Execution Model#
We can also mix the two execution models in a data flow graph of a DSP kernel. As a matter of fact, since we usually need to save the output of our DSP kernel to the global memory, we must use either a pure control-driven data flow graph or a mixed-model one.
Below is a piece of C++ code snippet specifying a simple example of a mixed-model data flow graph:
void worker(hls::stream<int>& in, hls::stream<int>& out) { int i = in.read(); int o = i * 2 + 1; out.write(o); } void read_in(int* in, int n, hls::stream<int>& out) { for (int i = 0; i < n; i++) { out.write(in[i]); } } void write_out(hls::stream<int>& in, int* out, int n) { for (int i = 0; i < n; i++) { out[i] = in.read(); } } void dut(int in[N], int out[N], int n) { hls_thread_local hls::split::round_robin<int, NP> split1; hls_thread_local hls::merge::round_robin<int, NP> merge1; #pragma HLS dataflow read_in(in, n, split1.in); // Task-Channels hls_thread_local hls::task t[NP]; for (int i = 0; i < NP; i++) { #pragma HLS unroll t[i](worker, split1.out[i], merge1.in[i]); } write_out(merge1.out, out, n); }
The top-level function of the kernel is
dut()with array argumentsinandoutare mapped to global memory. The dataflow region is specified to be the scope ofdut()within which there is a data-driven region specified by the arrayt[NP]ofNPworkertasks.The
hls::splitandhls::mergeclass objectssplit1andmerge1are demultiplexing and multiplexing FIFOs, respectively.For the case of
NP=4, the data flow graph inferred by Vitis HLS is shown below:
(3.5)#\[\begin{split}\begin{equation} \boxed{\text{in}} \rightarrow \text{read_in} \ \ \begin{array}{c} \nearrow {}^{\displaystyle t[0]} \searrow \\ \rightarrow {\displaystyle t[1]} \rightarrow \\ \rightarrow {\displaystyle t[2]} \rightarrow \\ \searrow {}_{\displaystyle t[3]} \nearrow \end{array} \ \ \text{write_out} \rightarrow \boxed{\text{out}} \end{equation}\end{split}\]